Automatické sťahovanie zmlúv
Robot pravidelne navštevuje adresu XML feed-u obsahujúci zoznam liniek na zmluvy vo formáte XML, ktoré sa následne synchronizujú so zmluvami v CRZ. Na základe výsledkov spracovania sa vytvárajú záznamy/reporty o návštevách feedu a príslušnych liniek zmlúv.
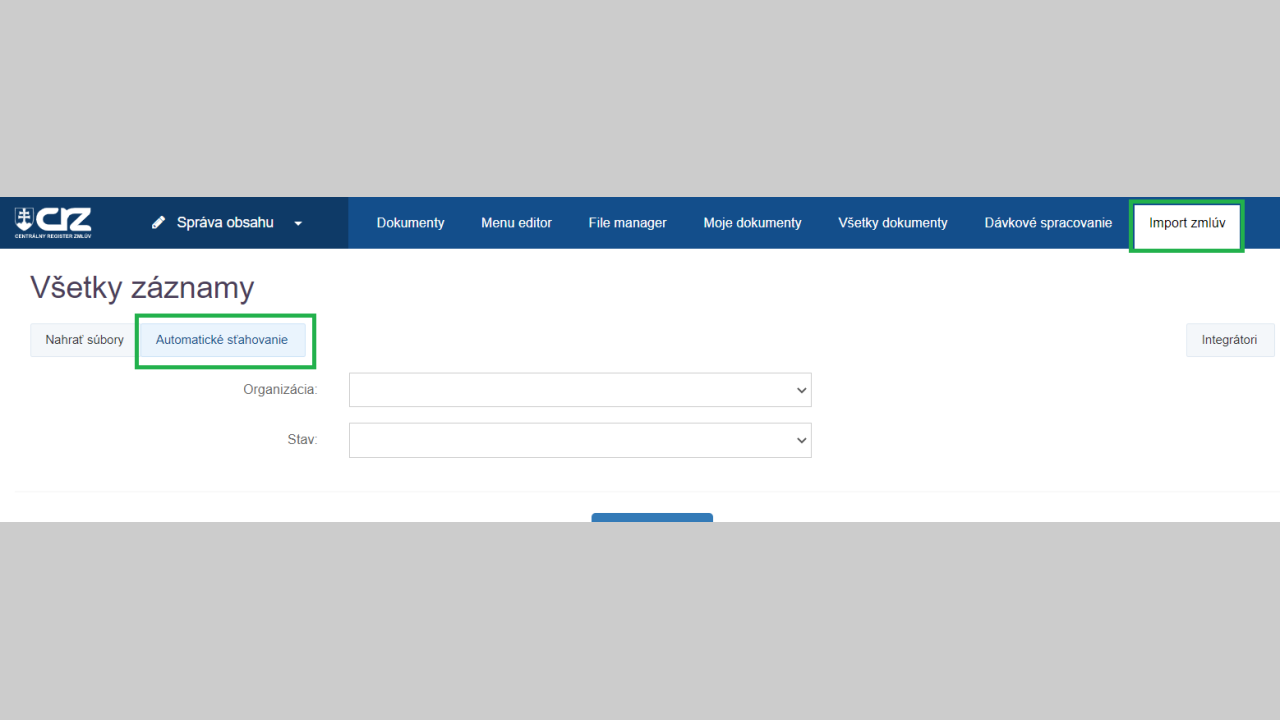
Pridanie nového automatického sťahovania
Automatické sťahovanie je možné nastaviť/pridať v module Import zmlúv v časti Automatické sťahovanie. Pre pridanie nového automatického sťahovania kliknite na tlačidlo Pridať automatické sťahovanie.
Vo formulári vyplňte príslušné polia:
- organizácia - vyberte jednu z organizácií, pre ktorú budú zmluvy synchronizované
- link na koncový bod - adresa XML feed-u obsahujúci zoznam liniek na zmluvy vo formáte XML (viď časť technická špecifikácia).
- technický email - emailová adresa, na ktorú budu odosielané notifikácie alebo potvrdenia
- zasielat notifikácie - zaškrtnite ak chcete dostávať notifikácie/potvrdenia
- aktívny - stav, či sa má automatické sťahovanie vykonávať (v prípade vypnutia len nechať odškrtnuté pole)
Záznamy spracovania automatického sťahovania robotom
Po pridaní automatického sťahovania sa zobrazí položka daného sťahovania v zozname automatických sťahovaní. Po kliknutí na položku máte k dispozícii 3 záložky: nastavenia, návštevy a linky. V nastaveniach vidíte prehľad nastavení automatického sťahovania a zároveň tu máte možnosť zmeniť jeho parametre. Návštevy a linky slúžia ako report spracovania robotom.
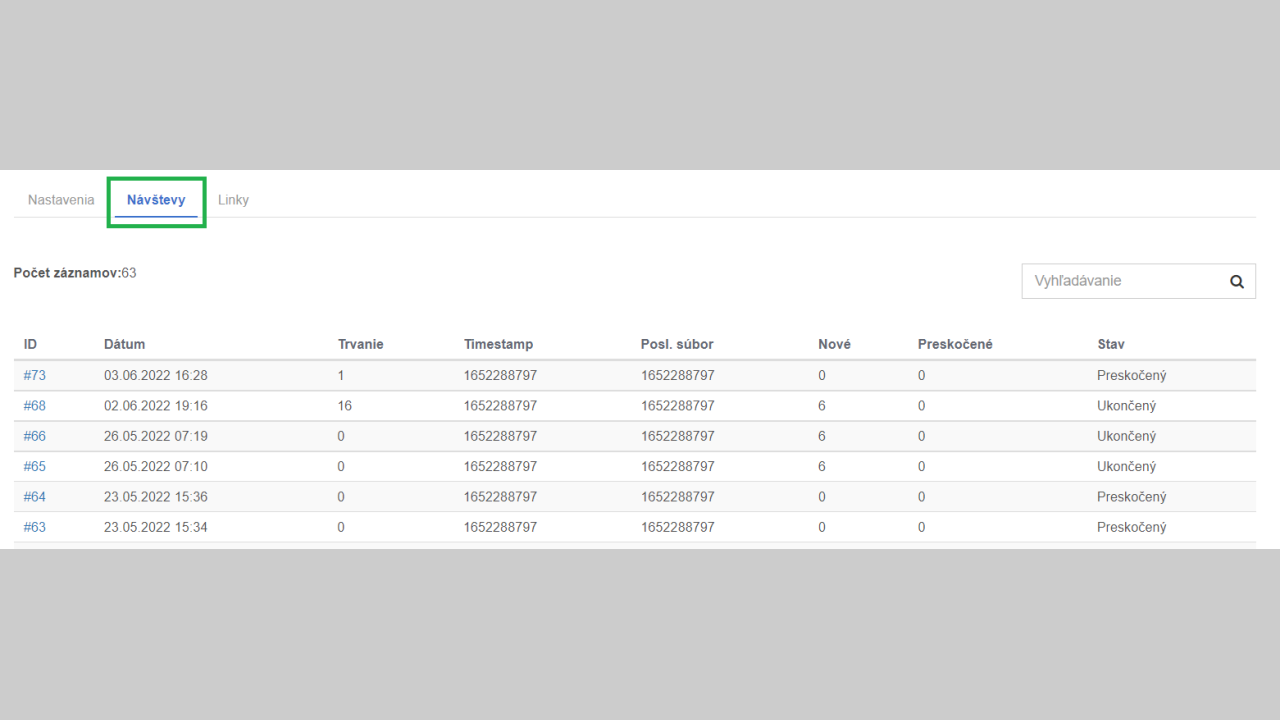
Návštevy
V časti návštevy je tabuľka so záznamami jednotlivých spracovaní/návštev robota. Zakaždým, ako robot spracuje XML feed, tak vytvorí príslušný záznam s údajmi o danej návšteve. V zázname môžete vidieť nasledujúce údaje:
- ID - identifikátor záznamu - odkaz na detail
- Dátum - kedy spracovanie prebehlo
- Trvanie - ako dlho spracovanie trvalo
- Timestamp - čas vo formáte timestamp
- Posl. súbor - posledný spracovaný súbor
- Nové - koľko nových zmlúv/liniek spracovalo
- Preskočené - koľko liniek bolo preskočených
- Stav - stav spracovania
Pre zobrazenie podrobnejších údajov kliknite na detail návštevy.
Linky
Každa linka predstavuje spracovanie položky XML feed-u - zmluvy vo formáte XML.
Každý záznam obsahuje:
- ID - identifikátor záznamu - odkaz na detail
- Dátum - kedy bola linka/XML súbor zmluvy spracovaný
- URL - URL adresa súboru
- Hash - hash dát XML súboru
- Hash content - hash dát zmluvy
V prípade, že sa hashe nezhodujú, identifikátor je sfarbený načerveno.
Pre zobrazenie podrobnejších údajov kliknite na detail návštevy.
Technická špecifikácia
Robot pre sťahovanie zmlúv v pravidelných intervaloch (3×denne) najskôr sťahuje obsah z lokality definovanej v nastaveniach automatického sťahovania. Robot očakáva, že na danej lokalite bude umiestnený zoznam súborov vo formáte XML.
Definícia schémy pre formát XML je uvedená na adrese: http://www.crz.gov.sk/schema/robot.xsd
Každá položka so súborom obsahuje nasledujúce parametre:
path - Názov súboru resp. cesta k súboru vždy udávaná relatívne k zadanému zdroju v aplikácii CRZ. Napr. zmluva1.xml
time - Čas publikovania súboru vo formáte timestamp. Robot vždy berie do úvahy len zmluvy novšie ako je posledná stiahnutá zmluva. Odporúčame ako dátum dávať čas umiestnenia súboru na server.
hash - MD5 hash súboru. XML robot ho používa na kontrolu duplicitného sťahovania súborov a tiež kontrolu prenosu súboru (MD5 hash musí byť rovnaký aj po stiahnutí súboru).
Odosielané parametre:
Pri pokuse stiahnuť súbor z definovanej lokality XML robot odosiela aj nasledujúce porametre:
datum - timestamp poslednej stiahnutej zmluvy. Požaduje sa generovanie zoznamov zmlúv iba s dátumom nie starším ako poslaný timestamp (teda dátum zmlúv by mal byť >= zaslaný timestamp).
Príklad generovania zoznamu súborov
Uvedený príklad (PHP) generuje zoznam súborov na základe aktuálnych súborov v adresári.
<?
$path='.';
$d = dir($path);
header("Content-type: text/xml");
print ''."\n";
print "\n";
$datum=isset($_REQUEST['datum'])?((integer) $_REQUEST['datum']):0;
while (false !== ($entry = $d->read())):
if (is_file($path.'/'.$entry) and (pathinfo($path.'/'.$entry,PATHINFO_EXTENSION)=='xml') and
(filemtime($path.'/'.$entry)>=$datum)):
print " \n";
print " ".htmlspecialchars($entry)."\n";
print " \n";
print " ".md5_file($path.'/'.$entry)."\n";
print " \n";
endif;
endwhile;
$d->close();
print "\n";
?>